Prototype
The Prototype Design Pattern
- Spawner 를 통해 Monster가 생성된다고 가정하자.
이 Spawner는 Monster 종류마다 따로 있다. - 이 때 brute-force로 구현하고자하면 아래와 같은 상속구조를 가지도록 할 수 있다.
![]()
- 프로토타입으로 이를 구현하면, 이를 좀 간결하게 구현할 수 있다.
- 어떤 객체가 자기와 비슷한 객체를 스폰할 수 있게된다.
- Monster 객체를 자신과 비슷한 객체를 생성하는 프로토타입 객체로 만드는것.

1
2
3
4
5
6
7
8
class Monster
{
public:
virtual ~Monster() {}
virtual Monster* clone() = 0;
// Other stuff...
};
- Monster 하위 클래스에서, 새 객체를 리턴하도록 구현해야한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class Ghost : public Monster {
public:
Ghost(int health, int speed)
: health_(health),
speed_(speed)
{}
virtual Monster* clone()
{
return new Ghost(health_, speed_);
}
private:
int health_;
int speed_;
};
- 이를 상속받는 클래스를 사용하면, 이제 종류별로 만들 필요 없이 하나만 만들면 된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
class Spawner
{
public:
Spawner(Monster* prototype)
: prototype_(prototype)
{}
Monster* spawnMonster()
{
return prototype_->clone();
}
private:
Monster* prototype_;
};
- Spawner는 Monster 객체를 생산하는 역할만 한다.
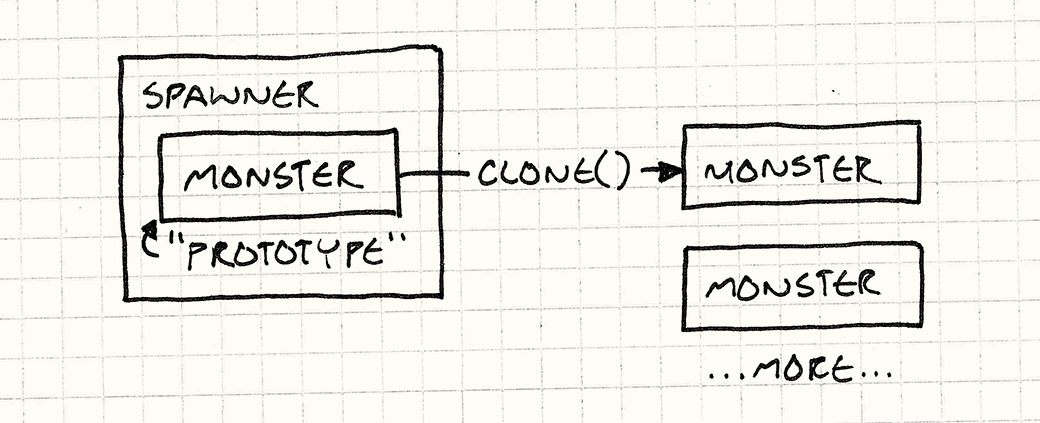
- 아래와 같이 사용할 수 있다.
1
2
Monster* ghostPrototype = new Ghost(15, 3);
Spawner* ghostSpawner = new Spawner(ghostPrototype);
- 장점
- 클래스와 상태를 클론한다.
- 프로토타입으로 사용하는 객체를 잘 설정하면, 여러 상태를 가진 몬스터(빠른, 약한, 강한)를 생성하는 스포너를 만들 수 있다.
How well does it work?
깊은 복사(deep clone), 얕은 복사(shallow clone) 등 구현할 때 생각할만한 것들이 많다.
요즘 나오는 게임엔진은 이처럼 몬스터마다 클래스를 따로 만들지 않는다.
클래스 상속구조가 복잡하면, 유지보수가 힘들다.
- 요즘은 Component 와 Type Object을 사용하여 각각의 클래스를 만들지 않고 다양한 종류의 entity를 모델링한다.
Spawn functions
- 각 몬스터마다 별도의 스포너 클래스를 만드는 대신 스폰 함수를 만들 수 있다.
1
2
3
4
Monster* spawnGhost()
{
return new Ghost();
}
- 몬스터 종류마다 클래스를 만드는 것보다 코드가 적다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 함수포인터 typedef : https://stackoverflow.com/questions/4295432/typedef-function-pointer
typedef Monster* (*SpawnCallback)();
class Spawner
{
public:
Spawner(SpawnCallback spawn)
: spawn_(spawn)
{}
Monster* spawnMonster()
{
return spawn_();
}
private:
SpawnCallback spawn_;
};
- 다음과 같이 객체를 생성한다.
1
2
Spawner* ghostSpawner = new Spawner(spawnGhost);
Templates
- 특정 몬스터 클래스를 생성하는 함수들을 하드코딩하기 싫다면, 몬스터 클래스를 템플릿 타입 매개변수로 전달하면된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
class Spawner
{
public:
virtual ~Spawner() {}
virtual Monster* spawnMonster() = 0;
};
template <class T>
class SpawnerFor : public Spawner
{
public:
virtual Monster* spawnMonster() { return new T(); }
};
- 아래와 같이 사용할 수 있다.
1
Spawner* ghostSpawner = new SpawnerFor<Ghost>();
First-class types
- C++ 의 타입들은 first-class가 아니라 위처럼 타입을 넘겨야한다.
JS, python, ruby등과 같은 동적 타입 언어(dynamically-typed language)는 더 직접적으로 해결할 수 있다.
- 그냥 원하는 몬스터를 런타임 객체를 그냥 전달.
사실 저자는 이 디자인 패턴이 이상적으로 사용할 수 있는 곳이 없다고 생각한다.
- 저자는 언어 패러다임으로서의 프로토타입에대해 이후 기술한다.
The Prototype Language Paradigm
- OOP가 데이터와 코드를 묶어주는 ‘객체’를 직접 정의할 수 있게 한다.
- 상태와 동작을 함께 묶는것.
Self
셀프는 클래스는 없지만 OOP에서 할 수 있는걸 다 할 수 있는 언어이다.
- 클래스 기반 언어보다 더 객체 지향이다.
클래스기반 언어
- 상태가 인스턴스 안에 들어있다.
- 동작은 클래스에 있다.(메서드 호출 시 인스턴스의 클래스를 찾음)
- 상태와 메서드는 다르다.

- 셀프에는 이런 구별이 없다. - 무엇이든 객체에서 바로 찾을 수 있다. - 인스턴스는 상태와 동작 둘다 가짐.
![]()

C++에서는 가상 메서드를 호출할 때, 먼저 인스턴스에서 vtable 포인터를 구하고, 다시 vtable로부터 메서드를 찾는다.
vtable: 컴파일 시 가상함수가 정의된 클래스가 있으면, 가상 함수 테이블이 만들어져, 바이너리 ‘rdata’ 영역에 기록되며, 해당 클래스로 만들어진 객체에서 함수를 호출할 때 해당 클래스의 vtable을 참조해서 함수를 호출한다.
- 클래스 기반 언어
- 약간의 단점: 상속
- 장점: 다형성을 통한 코드 재사용과 중복 코드 최소화
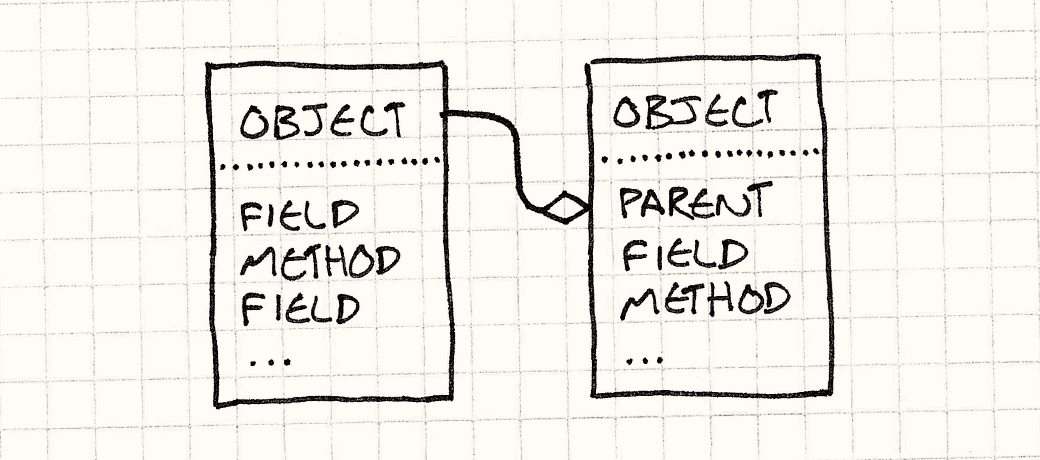
셀프에서는 클래스의 장점을 얻을 수 있는 위임(delegation) 개념이 있다.
해당 객체에 필드나 메서드가 없으면, 상위(parent) 객체를 찾는다.
- 상위 객체는 그냥 다른 객체 레퍼런스
- 상위레벨에서 찾는걸 계속 반복한다.
- 즉, 위임하는것을 반복한다.
![]()
클래스 == 자기 자신의 인스턴스 factory
- 셀프에서는 프로토타입과 같이 복제(clone)한다.
- 즉, 모든 객체가 프로토타입 디자인 패턴을 지원하는것.
How did it go?
언어를 구현하는건 비교적 쉽지만 사용자는 사용하기 복잡하다.
이해하기 어려움.
What about JavaScript?
- 자스는 프로토타입 기반.
- 셀프로부터 영감 받아 만들어진것.
- 객체 == 아무 속성 값이나 가짐
- 속성 == 필드나 메서드(필드로서 저장된 함수)
- 객체 == ‘프로토타입’이라고 부르는 다른 객체를 지정 가능
- 자기 자신에 없는 필드를 프로토타입에 위임 가능
하지만 클래스 기반 언어에 더 가까움.
- 복제(clone) 기능이 없기 때문.
- 자스는 자료형을 정의하는 객체로부터 new를 호출하는 생성자 함수를 통해 객체를 생성한다.
- 상태는 인스턴스 그 자체에 저장한다.
- 동작은 자료형이 같은 객체 모두가 공유하는 메서드 집합을 대표하는 별도 객체인 프로토타입에 저장되고, 위임을 통해 간접 접근됨.
Prototypes for Data Modeling
사실상 프로토타입은 사용하기 어려움.
옛날에는 모든걸 절차적으로 생성했다.(용량을 줄이기 위해)
요즘 게임 콘텐츠는 모두 데이터에 정의됨.
프로그래밍 언어를 사용하는 이유: 복잡성을 제어할 수 있는 수단을 가지고 있음.
게임 데이터도 규모가 일정 이상되면, 코드와 비슷한 기능이 필요하다.
- 데이터 모델링, 프로토타입과 위임을 활용해 데이터를 재사용하는 기법
데이터
몬스터와 아이템 속성을 파일 어딘가에 정의한다고 해보자.
- Json을 많이 사용함.
- 키/값 구조로 이루어진 데이터 개체로 맵, 속성목록(property bag) 라고 불림
데이터 개체 관련 용어 => 범용 디자인 패턴
아래와 같이 몬스터 구성할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
{
"name": "goblin grunt",
"minHealth": 20,
"maxHealth": 30,
"resists": ["cold", "poison"],
"weaknesses": ["fire", "light"]
}
{
"name": "goblin wizard",
"minHealth": 20,
"maxHealth": 30,
"resists": ["cold", "poison"],
"weaknesses": ["fire", "light"],
"spells": ["fire ball", "lightning bolt"]
}
{
"name": "goblin archer",
"minHealth": 20,
"maxHealth": 30,
"resists": ["cold", "poison"],
"weaknesses": ["fire", "light"],
"attacks": ["short bow"]
}
- 이러면 개체에 중복이 많다.
- 유지보수를 어렵게하는 원인
- JSON에는 추상 자료형이라는 개념이 없다.
- 객체에 ‘프로토타입’필드가 있어서, 여기에서 위임하는 다른 객체의 이름을 찾을 수 있다고 가정하자.
- 첫 번째 객체에서 원하는 속성이 없으면, 프로토타입 필드가 가리키는 객체에서 대신찾는다.
즉, 프로토타입 필드는 실제 데이터가 아닌 메타데이터이다.
- 첫 번째 객체에서 원하는 속성이 없으면, 프로토타입 필드가 가리키는 객체에서 대신찾는다.
- 이제 아래와 같이 단순하게 만들 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
{
"name": "goblin grunt",
"minHealth": 20,
"maxHealth": 30,
"resists": ["cold", "poison"],
"weaknesses": ["fire", "light"]
}
{
"name": "goblin wizard",
"prototype": "goblin grunt",
"spells": ["fire ball", "lightning bolt"]
}
{
"name": "goblin archer",
"prototype": "goblin grunt",
"attacks": ["short bow"]
}
- 이제 반복 입력할 필요가 없다.
일회성 특수 개체가 자주 나오는 게임에 잘맞는 방식이다.
- 보스와 유니크 아이템은 일반 몹과 아이템을 약간 다듬어 만들 때가 많으므로, 프로토타입 방식의 위임을 사용하기 좋다.(조금 더 게임을 풍성하게)