최적화 패턴
- 하드웨어 성능을 끌어내기 위해
게임 속도를 높이는 데 사용되는 중간 수준(mid-level)의 패턴들
- 데이터 지역성 패턴: 컴퓨터 메모리 계층과 이를 활용하는 법
- 더티 플래그 패턴: 불필요한 계산
- 오브젝트 풀 패턴: 불필요한 객체 할당 피하는법
- 공간 분할 패턴: 게임 월드 공간 내에서 객체들을 빠르게 배치할 수 있게 해줌
데이터 지역성
- CPU 캐시를 최대한 활용할 수 있도록 데이터를 배치해 메모리 접근 속도를 높인다.
Motivation
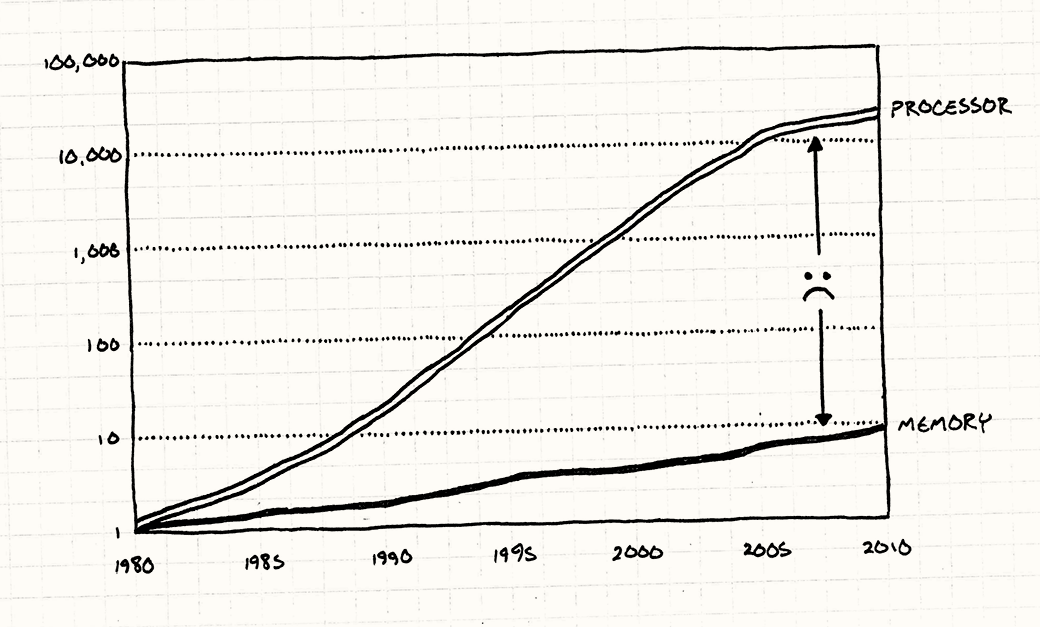
- 무어의 법칙으로 하드웨어는 급속히 발달했다.
하지만 데이터 연산은 훨씬 빨라졌지만, 데이터를 가져오는 건 그렇게 빨라지지 않았다.
![]()
- 주 메모리 ==데이터==> 레지스터
- RAM은 CPU 속도를 전혀 따라잡지 못함.
- RAM에서 데이터를 한 바이트 가져오는 데 몇백 CPU 사이클 정도가 걸린다.(2010년대)
RAM은 디스크 드라이브와는 달리 이론적으로는 어느 데이터나 같은 시간 안에 접근할 수 있어서 ‘임의접근기억장치’라고 부른다. RAM은 디스크처럼 순차 읽기를 걱정하지 않아도 된다.(그래도 완전히 임의접근이 가능한건 아님)
- RAM에서 데이터를 한 바이트 가져오는 데 몇백 CPU 사이클 정도가 걸린다.(2010년대)
- CPU는 대부분의 시간을 데이터를 기다리며 대기상태로 있지 않는다.
CPU를 위한 팰릿
- CPU 캐싱
- CPU안에 작은 메모리, 메인메모리보다 훨씬 빠르게 CPU에 데이터를 전달할 수 있다.
- CPU 칩 안에 들어가기 때문에, 빠르고 용량이 작고 비싸다(static RAM, SRAM)
- 캐시: 작은 크기의 메모리 (칩내부: L1캐시)
- 캐시 == 팰릿
- 칩이 RAM으로부터 데이터를 한 바이트라도 가져와야 할 경우, RAM은 보통(64~128바이트 정도의) 연속된 메모리를 선택해 캐시에 복사함다. - 이런 메모리 덩어리를 캐시 라인(cache line)이라고 한다.
L1, L2, L3와 같이 여러 계층으로 나뉜다. 숫자가 올라갈수록 크기는 커지지만, 속도는 느려진다.
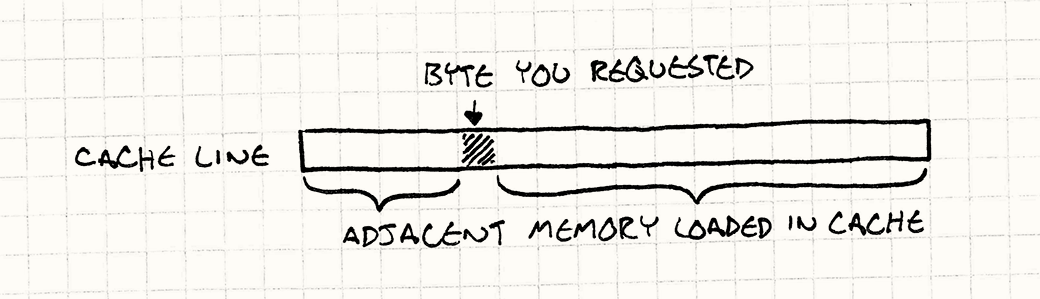
- 필요한 데이터가 캐시 라인 안에 들어 있다면 CPU는 RAM보다 빠른 캐시로부터 데이터를 가져온다.
캐시 라인이 여러개 => 캐시 집합(cache associativity)
- 캐시 히트: 캐시에서 원하는 데이터를 찾는 것
- 캐시 미스: 데이터를 찾지 못해 주 메모리에서 데이터를 가져오는 것
- 캐시 미스가 발생하면 CPU는 멈춘다.
- 이렇게 기다리는 시간을 최대한 피해야한다.
Wait, data is performance?
- 캐시를 뒤엎는 코드: 저자가 테스트했을 때, 속도가 50배 차이남.
- 데이터를 어떻게 두느냐가 성능에 직접적인 영향을 미침.
- 캐시 최적화는 굉장히 큰 주제: 명령어 캐시 같은것도 있다.
- 코드 역시 메모리에 존재, CPU에 로드되어야함
캐시 뒤엎기(cache thrash): 캐시 무효화가 계속 반복되는 현상
이 장에선 자료구조가 성능에 어떻게 영향을 미치는지에 대해 간단한 기법 몇가지를 소개함.
- 모든 기법의 결론: 캐시 라인에 있는 값을 더 많이 사용할수록 더 빠르게 만들 수 있다.
즉, 자료구조를 잘 만들어서 처리하려는 값이 메모리 내에서 서로 가까이 붙어 있도록 해야한다.
여기에선 스레드가 하나라는 가정이 있음. 두 스레드에 같은 캐시 라인에 들어 있는 데이터를 고치려 든다면, 두 코어 모두 비싼 캐시 동기화 작업을 해야한다. => 캐시 일관성 프로톨콜에 대한 내용: “프로그래머가 몰랐던 멀티 코더 CPU이야기”
- 이렇게 하려면 아래 그림처럼 실제 객체 데이터가 순서대로 들어있어야 한다.
![]()
The pattern
- CPU는 메모리 접근 속도를 높이기 위해 캐시를 여러개 둔다.
- 캐시를 사용하면 최근에 접근한 메모리 근처에 있는 메모리를 훨씬 빠르게 접근할 수 있다.
- 데이터 지역성을 높읠수록, 즉, 데이터를 처리하는 순서대로 연속된 메모리에 둘수록 캐시를 통해서 성느응ㄹ 향상할 수 있다.
언제 사용?
데이터 지역성 패턴: 성능 문제가 있을 경우 사용해야함.
- 필요 없는 곳을 최적화해 봐야 코드만 복잡해지고 유연성만 떨어짐.
성능 문제가 캐시 미스 때문인지 확인해야함.
- 프로파이링: 쿠드 두 지점 사이에 얼마나 시간이 지났는지 타이머 코드 넣음.
- 캐시 사용량을 확인하려면 더 복잡한 방법이 필요
- 지원하는 프로파일러들 사용해야함.
- 개발하는 내내 자료구조를 캐시하기 좋게 만들려고 노력할 필요가 있다.
프로파일러: Cachegrind 는 프로그램을 가상의 CPU와 캐시 계층 위에서 실행한 뒤에 모든 캐시 상호작용 결과를 알려준다.
가상 함수 호출: CPU가 객체의 vtable에서 실제로 호출할 함수 포인터를 찾아야함. => 포인터 추적 발생 => 캐시 미스
주의사항
추상화: 소프트웨어 아키텍처의 전형적인 특징 중 하나
- 객체 지향 언어 => 인터페이스 사용하여 디커플링
- C++에서 인터페이스를 사용하려면 포인터나 레퍼런스를 통해 객체에 접근해야함.
- 포인터 사용 => 메모리를 여기저기서 찾아가야 하기 때문에, 캐시미스가 발생한다.
- 추상화를 일부 희생해야 데이터 지역성을 사용할 수 있음.
- 상속, 인터페이스로부터 얻을 수 있는 이득을 포기해야함.
샘플 코드
연속 배열
게임 루프부터 시작
- 게임 개체는 컴포넌트 패턴을 이용해 AI, 물리, 렌더링 같은 분야로 나눈다.
컴포넌트에 직접 접근하는 게임루프
- GameEntity 클래스는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class GameEntity
{
public:
GameEntity(AIComponent* ai,
PhysicsComponent* physics,
RenderComponent* render)
: ai_(ai), physics_(physics), render_(render)
{}
AIComponent* ai() { return ai_; }
PhysicsComponent* physics() { return physics_; }
RenderComponent* render() { return render_; }
private:
AIComponent* ai_;
PhysicsComponent* physics_;
RenderComponent* render_;
};
- 각 컴포넌트에는 벡터 몇 개 또는 행렬 한 개 같은 몇몇 상태와 이를 업데이트하기 위한 메서드가 들어 있다.(업데이트 메서드 패턴 사용)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
class AIComponent
{
public:
void update() { /* Work with and modify state... */ }
private:
// Goals, mood, etc. ...
};
class PhysicsComponent
{
public:
void update() { /* Work with and modify state... */ }
private:
// Rigid body, velocity, mass, etc. ...
};
class RenderComponent
{
public:
void render() { /* Work with and modify state... */ }
private:
// Mesh, textures, shaders, etc. ...
};
- 월드에 있는 모든 개체는 거대한 포인터 배열 하나로 관리한다.
매번 게임 루프를 돌 때마다 다음 작업을 수행한다.
- 모든 개체의 AI 컴포넌트를 업데이트한다.
- 모든 개체의 물리 컴포넌트를 업데이트한다.
- 렌더링 컴포넌트를 통해서 모든 개체를 렌더링한다.
- 대부분 다음과 같이 구현한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
while (!gameOver)
{
// Process AI.
for (int i = 0; i < numEntities; i++)
{
entities[i]->ai()->update();
}
// Update physics.
for (int i = 0; i < numEntities; i++)
{
entities[i]->physics()->update();
}
// Draw to screen.
for (int i = 0; i < numEntities; i++)
{
entities[i]->render()->render();
}
// Other game loop machinery for timing...
}
- 이 코드는 단순히 캐시를 뒤엎는 정도가 아니라 더 심각함.
아래와 같은 일들이 일어남.
- 게임 개체가 배열에 포인터로 저장되어 있음, 배열 값에 접근할 때마다 포인터를 따라가면서 캐시 미스가 발생
- 게임 개체는 컴포넌트를 포인터로 들고 있어서 캐시 미스 발생
- 컴포넌트를 업데이트
- 모든 개체의 모든 컴포넌트에 대해 같은 작업 반복
포인터 추적(pointer chasing): 포인터를 따라다니느라 시간을 낭비하는것
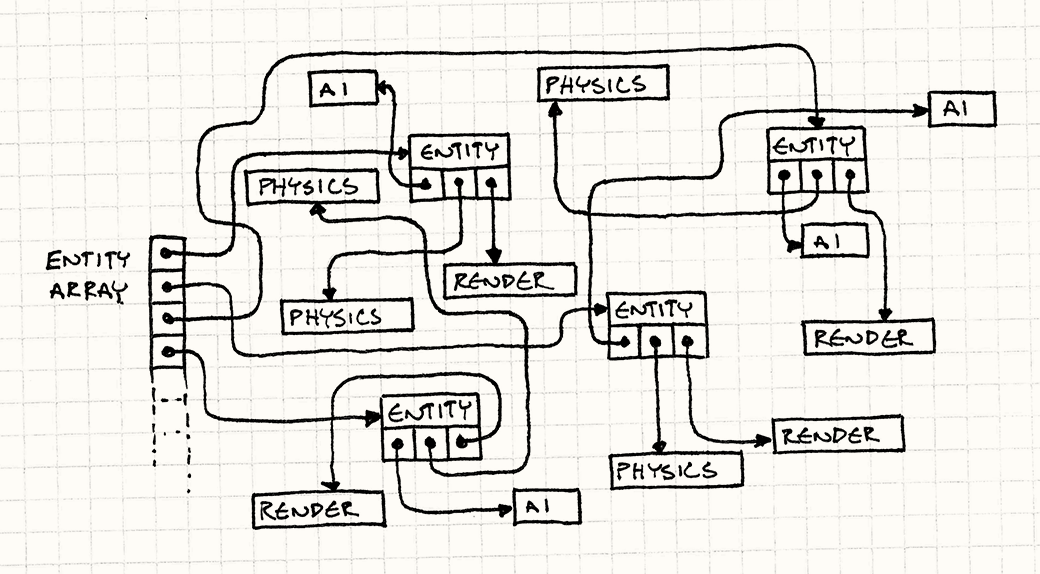
이들 객체의 메모리 배치는 메모리 메니저만 알고, 우리는 전혀 모름 -개체가 할당, 해제를 반복할수록 힙은 점점 어질러짐.
![]()
개선해보자.
- 게임 루프에는 컴포넌트만 있으면 된다.
- 다음과 같이 AI, 물리, 렌더링 컴포넌트 타입별로 큰 배열을 준비한다.
1 2 3 4 5 6
AIComponent* aiComponents = new AIComponent[MAX_ENTITIES]; PhysicsComponent* physicsComponents = new PhysicsComponent[MAX_ENTITIES]; RenderComponent* renderComponents = new RenderComponent[MAX_ENTITIES];
- 배열에 컴포넌트가 포인터가 아닌 컴포넌트 객체가 들어간다는 점이 중요
모든 데이터가 배열 안에 나란히 들어 있기 때문에 게임 루프에서는 객체에 바로 접근할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
while (!gameOver)
{
// Process AI.
for (int i = 0; i < numEntities; i++)
{
aiComponents[i].update();
}
// Update physics.
for (int i = 0; i < numEntities; i++)
{
physicsComponents[i].update();
}
// Draw to screen.
for (int i = 0; i < numEntities; i++)
{
renderComponents[i].render();
}
// Other game loop machinery for timing...
}
간접 참조 연산자(->)의 개수를 줄인것을 볼 수 있음. 이는 데이터 지역성을 높엿다는 것을 의미함.
- 포인터 추적을 제거했으므로, 메모리를 여기저기 뒤지지 않고, 연속된 배열 세 개를 쭉 따라갈 수 있다.
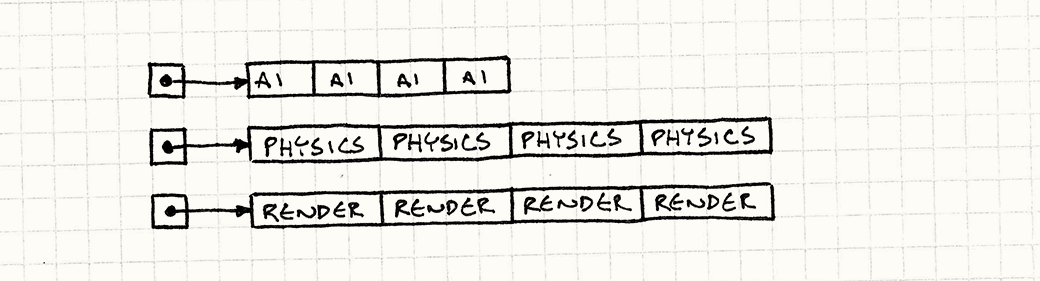
- 변경된 코드는 연속된 바이트 스트림을 CPU에 계속 밀어 넣는다.
- 저자 테스트 결과 업데이트 루프가 50배 빨라짐.
그리고 캡슐화를 많이 해치지 않는다.
- 컴포넌트는 자기 데이터와 메서드가 있다는 점에서 여전히 잘 캡슐화되어 있다.
- 단순히 컴포넌트가 사용되는 방식만 변함.
GameEntity클래스를 제거할 필요는 없다.- 여기에 컴포넌트에 대한 포인터를 가지도록 만들 수 있다.
- 포인터는 이들 배열에 있는 객체를 가리킨다.
- 개념적인 ‘게임 개체’와 개체에 포함되어 있는 것 전부를 한 객체로 다른 코드에 전달 할 수 있기 때문에 유용함.
- 게임 루프 == 성능에 민감, 게임 개체를 우회해서 게임 개체 내부 데이터(컴포넌트)에 직접 접근했다는 점이 중요
정렬된 데이터
- 파티클 시스템을 살펴보자.
- 앞의 예제처럼 파티클들을 하나의 배열에 두고, 간단한 관리 클래스로 래핑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class Particle
{
public:
void update() { /* Gravity, etc. ... */ }
// Position, velocity, etc. ...
};
class ParticleSystem
{
public:
ParticleSystem()
: numParticles_(0)
{}
void update();
private:
static const int MAX_PARTICLES = 100000;
int numParticles_;
Particle particles_[MAX_PARTICLES];
};
- 파티클 시스템의 업데이트 메서드는 다음과 같은 기본 기능만 한다.
1
2
3
4
5
6
7
void ParticleSystem::update()
{
for (int i = 0; i < numParticles_; i++)
{
particles_[i].update();
}
}
- 하지만, 파티클 객체를 매번 전부 처리할 필요는 없다.
- 파티클 시스템에는 고정크기 객체 풀이 있지만, 풀에 있는 파티클이 전부 화면에서 반짝거리는 건 아님.
- 아래와 같이 해결할 수 있음.
1
2
3
4
5
6
7
for (int i = 0; i < numParticles_; i++)
{
if (particles_[i].isActive())
{
particles_[i].update();
}
}
이 코드의 문제점: 모든 파키클에 대해 if 검사 => CPU 분기 예측 실패를 겪으면서 파이프라인 지연(pipeline stall)이 생길 수 있음.
CPU 분기 예측: 이전에 어떻게 분기했는지 예측, 하지만 활성 비활성이 반복될 경우 이 예측의 실패율은 올라감, 그러므로 파이프라인을 정리(flush)하고, 다시 시작해야하는 빈도가 증가하게됨
- 위와 같이 코드를 짜면, 업데이트 루프에서 모든 파티클에 대해서 이 값을 검사함.
- 활성 파티클이 적을수록, 메모리를 더 자주 건너뛰게됨.(비활성화 => 로딩한 데이터 무용지물)
- 캐시미스 발생 => 배열이 크고, 비활성 파티클이 많으면 캐시 뒤엎기 문제 발생
이처럼 연속적인 배열에 둔다해도, 실제로 처리할 객체가 배열에 연속되어 있지 않으면 도움되지 않음
- 활성 여부를 플래그로 검사하지 않고, 활성 파티클만 앞에 모아두면된다.
- 그러면 다음과 같이 수정할 수 있다.
1
2
3
4
for (int i = 0; i < numActive_; i++)
{
particles[i].update();
}
매 프레임마다 퀵소트하는것이 아니라, 활성 객체를 앞에 모아두기만 하면된다.
파티클이 활성화 되면, 이를 비활성 파티클 중에서 맨 앞에 있는것과 스왑하면 끝
- 처음: 모든 파티클이 비활성 상태로 정리
- 배열의 정리 상태: 파티클의 활성 상태가 변할 때만 깨짐
1
2
3
4
5
6
7
8
9
10
11
12
13
14
void ParticleSystem::activateParticle(int index)
{
// Shouldn't already be active!
assert(index > numActive_); // assert(index>=numActive_)
// Swap it with the first inactive particle
// right after the active ones.
Particle temp = particles_[numActive_];
particles_[numActive_] = particles_[index];
particles_[index] = temp;
// Now there's one more.
numActive_++;
}
- 비활성화는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
void ParticleSystem::deactivateParticle(int index)
{
// Shouldn't already be inactive!
//assert(index < numActive_);
assert(index <= numActive_);
// There's one fewer.
numActive_--;
// Swap it with the last active particle
// right before the inactive ones.
Particle temp = particles_[numActive_];
particles_[numActive_] = particles_[index];
particles_[index] = temp;
}
저자를 포함한 대부분의 프로그래머들은 이처럼 메모리에서 객체를 복사로 옮기기를 꺼려한다.
- 여러 바이트를 옮기는 것이 포인터를 할당하는 것에 비해서 무겁다고 느끼기 때문.
- 하지만 포인터 추적 비용을 생각하면 틀릴 수 있다.
- 캐시를 계속 채워놓는 경우, 메모리 복사가 더 쌀 수 있다.
이렇게 하면 객체지향성을 어느 정도 포기해야함
- Particle 클래스는 자시느이 활성 상태를 스스로 제어할 수 없음.
- 파티클을 활성화하려면 꼭
ParticleSystem클래스를 통해야함.
- 파티클을 활성화하려면 꼭
- Particle 클래스는 자시느이 활성 상태를 스스로 제어할 수 없음.
빈번한 코드와 한산한 코드 나누기
간단한 기법으로 캐시를 활용할 수 있는 예제
AI 컴포넌트에서 현재 재생 중인 애니메이션, 이동 중인 묙표 지점, 에너지 값 등이 들어 있어서 프레임마다 이 값을 확인하고 변경해야 한다.
1
2
3
4
5
6
7
8
9
10
class AIComponent
{
public:
void update() { /* ... */ }
private:
Animation* animation_;
double energy_;
Vector goalPos_;
};
- 하지만 AI 컴포넌트에는 사용 빈도수가 적은 상태도 있다.
- 죽은 뒤 아이템을 떨어뜨려야할 때가 그렇다.
- 이 ‘드랍’ 데이터는 개체가 죽었을 때 한 번만 사용된다.
1
2
3
4
5
6
7
8
9
10
11
12
class AIComponent
{
public:
void update() { /* ... */ }
private:
// Previous fields...
LootType drop_;
int minDrops_;
int maxDrops_;
double chanceOfDrop_;
};
- 컴포넌트 크기가 커져, 캐시 라인에 들어갈 컴포넌트 개수가 줄었다.
- 읽어야 할 전체 데이터 크기가 크다 보니, 캐시 미스가 더 자주 발생한다.
- 드랍 정보 == 업데이트에서 사용 안하고, 매 프레임마다 캐시로 읽어옴.
해결: ‘빈번한 코드와 한산한 코드를 나누는것(hot/cold spliting)’
- 데이터를 두 개로 분리해 한곳에는 매 프레임마다 필요로 하는 ‘빈번한(hot)’ 데이터와 상태를 두고, 다른 곳에는 ‘한산한(cold)’ 데이터, 즉 자주 사용하지 않는 것들을 모아둔다.
- 자주 사용 == 포인터를 거치지 않기
- 가끔 사용 == 포인터로 가리키게 함
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class AIComponent
{
public:
// Methods...
private:
Animation* animation_;
double energy_;
Vector goalPos_;
LootDrop* loot_;
};
class LootDrop
{
friend class AIComponent;
LootType drop_;
int minDrops_;
int maxDrops_;
double chanceOfDrop_;
};
더 많이 캐시에 올라갈 수 있다.
하지만, 이렇게 나누기 애매함.
- 실제 게임 코드에서는 분간하기 쉽지 않음.
- 최적화하기 위해서 연습, 노가다가 필요
한산한 데이터/ 빈번한 데이터 두 개의 배열에 나란히 두면 포인터 모두 제거 가능, 두 데이터는 각자의 배열에서 같은 인덱스 위에 있어 쉽게 찾을 수 있음.
디자인 결정
- 메모리 배치에 따라 성능이 변함
- 구현은 다양함.
- 자료구조나 전체 구조를 변경할 수 있음.
많은 사람이 캐시를 활용할 수 있도록 게임 코드를 디자인하게 만든 노엘 로피스의 유명한 글: ‘데이터 중심 디자인’, 번역
다형성(polymorphism)은 어떻게 할 것?
배열에는 있는 객체 크기가 모두 같다: 멤버 변수가 추가되지 않은 하위 클래스는 상위 클래스와 크기가 같음 => 억지로 배열에 집어넣을 수 있음.
- 정렬된 단일 자료형 객체 배열이라고 가정.
- 다형성, 동적 디스패치를 같이 사용하는 방법?
사용하지 않는다
요즘 상속을 과하게 사용하지 않는 편.
- 상속 없이 다형성의 유연함 => 타입 오브젝트 패턴
안전하고 쉬움.
- 모든 객체는 정확하게 같은 크기, 어떤 클래스를 다루고 있는지 정확하게 안다.
- 더 빠르다
- 동적 디스패치: vtable에서 메서드를 찾아본 다음에 포인터를 통해서 실제 코드를 찾아가야한다.(성능 비용)
- 유연하지 않다
- 객체간 동작을 다르게 할 수 없음
- 이를 동적 디스패치 없이 지원하기 위해 함수 안에 다중 선택문 같은걸 넣는다면, 코드가 지저분해짐
종류별로 다른 배열에 넣는다
다형성 사용: 어떤 자료형인지 모르는 객체의 특정 행동을 호출하고 싶은 경우.
종류별로 다른 컬렉션에 나눠담기
- 객체를 빈틈없이 담을 수 있음
- 한 가지 클래스 객체만 들어감 => 패딩(공용체 이용)도 없고, 그외 다른것도 들어갈 틈이 없음
- 정적 디스패치를 할 수 있다
- 종류별로 객체를 나눔 => 다형성을 사용하지 않고, 일반적인 비-가상함수 호출가능
- 여러 컬렉션을 관리해야함
- 객체 종류가 많으면, 종류별로 배열을 관리하는 부담이 커질 수 있다.
- 모든 자료형을 알고 있어야 함
- 전체 클래스 자료형과 커플링됨.
- 다형성의 장점 == 확장성(open-ended)
- 어떤 인터페이스와 상호작용하는 코드 == 해당 인터페이스를 구현하는 구체 클래스가 아무리 많아도 이들과 전혀 커플링되지 않음.
하나의 컬렉션에 포인터를 모아놓는다
- 캐시를 신경쓰지 않는 경우
- 다형성 최대한 활용
어떤 크기의 객체라도 배열에서 포인터로 가리킴
- 유연
- 인터페이스 => 어떤 종류의 객체라도 기존 코드와 상호작용
- 캐시 친화적이지 않음
게임 개체는 어떻게 정의?
- 컴포넌트 패턴도 같이 사용할 경우, 연속된 배열에 모든 컴포넌트들이 이 배열에 들어감.
- 게임 루프 == 컴포넌트들을 직접 순회, 게임 개체 자체는 그다지 중요하지 않음.
개념적인(conceptual) ‘개체(entity)’를 표현하고 싶을 때에는 여전히 게임 개체 객체가 쓸모 있다.
- 그러면 어떻게 게임 개체 표현? 어떻게 컴포넌트 관리?
게임 개체 클래스가 자기 컴포넌트를 포인터로 들고 있을 경우
- 일반적인 OOP식 해결 방법
포인터를 가지므로, 메모리 어디에 들어있는지 모름
- 컴포넌트들을 연속된 배열에 저장 가능
- 컴포넌트들을 정렬된 배열에 둬서 순회 작업 최적화 가능
- 개체로부터 개체 컴포넌트 쉽게 얻기 가능
- 컴포넌트를 메모리에서 옮기기 어려움
- 개체가 포인터로 가리키므로, 배열내에서 컴포넌트의 위치가 변경되면 같이 변경해야함
게임 개체 클래스가 컴포넌트를 ID로 들고 있을 경우
컴포넌트를 ID나 인덱스를 통해서 찾게
- 컴포넌트별로 유일한 ID를 발급 => 배열에서 찾기
컴포넌트 배열에서 현재 위치를 ID와 매핑하는 해시 테이블로 관리
- 복잡함
- 포인터를 쓰는 것보다는 할 일이 많음.
- 시스템 구현, 디버깅, 메모리도 더 필요
- 더 느림
- 컴포넌트 찾기 => 해싱 작업 => 포인터를 따라가는 것보다는 느림
- 컴포넌트 ‘관리자’같은 것에 접근해야함
- 기본 아이디어: ID를 컴포넌트의 추상 식별자로 사용 => 실제 컴포넌트 객체 레퍼런스 얻기
- 무엇인가가 ID를 받아서 컴포넌트를 찾아줘야함 => 컴포넌트 배열을 래핑한 클래스가 그 역할을 맡음
- 이 경우
컴포넌트 레지스터리가 필요함.
게임 개체가 단순히 ID일 경우
- 몇몇 게임에서 사용하는 최신 방식.
- 개체의 동작과 상태를 전부 컴포넌트로 관리 => 개체에는 컴포넌트 집합만 남음
컴포넌트들끼리 상호작용해야하기 때문에 개체는 여전히 필요
- 모든 컴포넌트는 자신이 속한 개체의 형제 컴포넌트에 접근할 수 있어야함.
- 모든 컴포넌트는 자신을 소유하는 개체의 ID를 기억해야함.
개체 클래스는 완전히 사라지고, 숫자만으로 컴포넌트를 묶을 수 있음.
- 개체가 단순해짐
- 개체가 비어 있음
- 단점: 모든 것이 컴포넌트
- 상태나 작동을 둘 곳이 없어짐
- 컴포넌트 패턴에 더 집중
- 개체 생명주기를 관리하지 않아도 됨
- 개체는 그저 단순한 값.
- 개체를 구성하는 모든 컴포넌트가 파괴될 때 죽음
- 특정 개체의 컴포넌트를 찾는 게 느릴 수 있음
- ‘개체가 컴포넌트들을 ID로 관리할 때’와 같은 문제지만 방향은 다름
- 컴포넌트 얻기 == ID로 : 작업 비용이 비쌀 수 있음
- 성능에 민감: 상호작용이 많은 경우, 자주 컴포넌트를 찾아야할 수 있음
- 해결: 컴포넌트를 종류별로 들고 있는 배열에서의 인덱스를 개체 ID로 삼는것
- 모든 개체가 같은 컴포넌트를 가지면, 컴포넌트 배열들을 완전히 병렬로 둘 수 있음
- 인덱스가 모두 같게.
- 하지만 병렬로 유지하기 어려움 (비활성화 등 정렬 필요)
관련 자료
- 이 패턴은 컴포넌트 패턴과 관련이 많음
- 컴포넌트 패턴 == 캐시 사용 최적화를 위해 가장 많이 사용되는 자료구조 중 하나
- 컴포넌트로 분리하면 큰 덩어리의 개체를 캐시에 적합한 크기로 나눌 수 있음.
- 컴포넌트 패턴 == 캐시 사용 최적화를 위해 가장 많이 사용되는 자료구조 중 하나
토니 알브레히트(Tony Albrecht)의 “Pitfalls of Object-Oriented Programming” 은 캐시 친화성을 위한 게임 데이터 구조 설계에 대해 다룬다.
- 데이터 지역성 패턴에서는 거의 언제나 단일 자료형을 하나의 연속된 배열에 나열하는 방식을 활용하고 있다.
- 객체는 시간이 지남에 따라 배열에 추가, 제거 => 오브젝트 풀 패턴과 비슷
- Artemis 게임엔진은 처음으로 ID만 가지고 게임 개체를 표현한 것으로 알려진 프레임워크이다.